Understanding Reinforcement Learning: An Introduction to Key Concepts
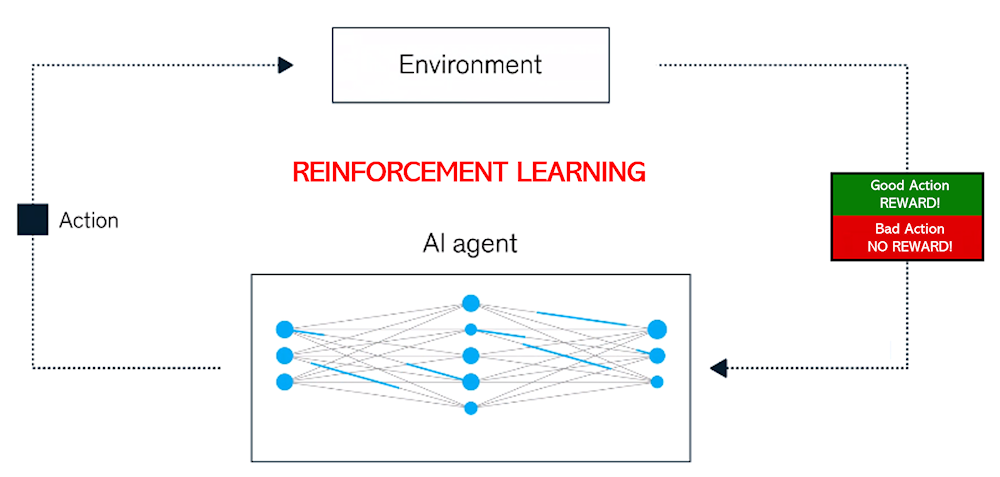
Reinforcement Learning (RL) is a branch of machine learning where an agent learns to make decisions by interacting with its environment in a sequential manner. The goal is to maximize a cumulative reward over time, typically by taking actions that lead to favorable outcomes. However, this process is often done under uncertainty, where the consequences of actions are not always clear. In this article, we will break down the essential components of RL, including Markov assumptions, types of decision-making processes, and key concepts like exploration vs. exploitation, and the different types of agents.
Sequential Learning Under Uncertainty
Reinforcement Learning revolves around the idea of sequential learning under uncertainty. At each step, an agent takes an action based on its current state, and in return, it receives feedback in the form of a reward and a new state. Over time, the agent learns the best policy — i.e., the best set of actions to take in various states — to maximize its cumulative reward.
The Markov Assumption
One of the key assumptions in Reinforcement Learning is the Markov assumption. According to this principle, the future state of the system depends only on the current state and action, not on the history of past states or actions. In other words, the future is independent of the past given the present. This simplifies decision-making, as agents can make predictions about future events based solely on the current state of the environment.
If we include all past history in our model, the system can be considered Markov. However, often for simplicity and efficiency, only the most recent observations (like the last four) may provide enough information to make optimal decisions. This approach is often good enough for practical applications, as considering an overly long history can introduce unnecessary complexity.
Partial Observability and Belief States
In many environments, an agent may not have access to the full history of the world. For instance, imagine you’re playing a game of poker. You can only see your own cards and the actions of other players, but not their cards. In this case, the agent must construct a belief state — a representation of what it believes about the environment, given the limited observations it has. This allows the agent to make decisions based on its best guess of the true state of the environment, even if it doesn’t have full information.
Types of Sequential Decision Processes
There are different frameworks within which agents operate, depending on the amount of information available and how actions affect the world.
Bandits
A bandit problem is a simpler form of decision-making process where an agent must choose actions (often called “arms” in this context), but the actions do not influence future observations. Bandits are often used to model situations where there are no delayed rewards, and the agent doesn’t need to worry about long-term consequences of its actions. In this setup, the agent simply tries to maximize immediate rewards based on the limited feedback it receives.
Markov Decision Processes (MDPs)
In Markov Decision Processes (MDPs), actions do influence the state of the world. The agent’s actions result in new states, which in turn yield rewards. An MDP provides a formal framework for decision-making in environments where both the current state and the actions taken by the agent impact future outcomes. MDPs are foundational to many RL algorithms.
Partially Observable Markov Decision Processes (POMDPs)
In some cases, agents do not have full visibility of the current state of the environment. In these situations, we use Partially Observable Markov Decision Processes (POMDPs). In a POMDP, the agent must infer the hidden states of the environment based on partial observations. This adds an additional layer of complexity, as the agent has to maintain a belief state, or a probabilistic estimate of what the true state might be, to make decisions.
How the World Changes: Deterministic vs. Stochastic
Another important distinction in RL is between deterministic and stochastic environments.
- Deterministic: Given a specific history and action, there is only one possible outcome. For example, in robotic control, when the agent takes a certain action (like moving a robot), the resulting state and reward are predictable.
- Stochastic: In stochastic environments, the agent’s actions lead to a range of possible outcomes. This is the case in many real-world applications, such as when a coin flip determines which airplane to board. The outcome of the action is uncertain, leading to various possible future states and rewards.
Algorithm Components
An RL agent typically has several key components that help it navigate and learn from its environment:
- Model: A representation of how the world changes in response to the agent’s actions.
- Policy: A function that maps the agent’s states to the actions it should take.
- Value function: A measure of the future rewards expected from a given state or action when following a particular policy.
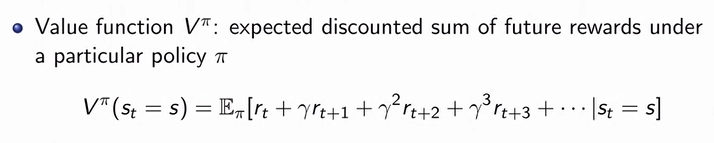
The policy is the main decision-making mechanism for the agent, determining how it selects actions based on its current state. If the environment is stochastic, the policy can be probabilistic, meaning the agent may select different actions based on a distribution of possible choices.
The value function is a way of estimating the future rewards the agent can expect by following a particular policy. It helps the agent decide which states or actions are more beneficial in the long run.
Types of Reinforcement Learning Agents
There are two main types of RL agents: model-based and model-free agents.
Model-based Agents
- These agents explicitly learn a model of the environment (i.e., how the world changes based on their actions).
- They may or may not have an explicit policy or value function, but they use the model to predict outcomes and plan their actions accordingly.
Model-free Agents
- Model-free agents learn directly from experience, without a model of how the world works.
- They either learn a value function (to estimate long-term rewards) or directly learn a policy.
Exploration vs. Exploitation
A fundamental challenge in reinforcement learning is the exploration vs. exploitation tradeoff.
- Exploration refers to trying new actions that the agent has not tried before, potentially discovering better ways to achieve rewards.
- Exploitation refers to choosing actions that are known to yield good rewards based on past experience. For example, if you always watch your favorite movie (exploitation), you may miss out on discovering a new favorite movie (exploration). Balancing these two strategies is key to optimizing long-term rewards.
Stationarity vs. Non-Stationarity
In some decision-making problems, the dynamics of the environment may change over time, leading to non-stationarity. In such cases, the agent’s decision-making process must adapt to these changes. For example, if you are deciding which flight to take, the choice may depend on the time of day, and your strategy might change depending on whether it’s morning or evening.
A stationary environment has consistent dynamics, meaning that the transition probabilities (how actions lead to different states) do not change over time.
Conclusion
Reinforcement learning is a powerful tool for solving sequential decision-making problems, but it comes with its own set of challenges. Understanding the basic principles, such as the Markov assumption, exploration vs. exploitation, and the different types of RL agents, is essential for designing effective RL systems. As RL continues to evolve, these foundational concepts will guide the development of more sophisticated algorithms and applications across a range of domains, from robotics to finance and beyond.
References : Stanford CS234: Reinforcement Learning | Winter 2019 | Lecture 1
*This post originally appeared on my Medium
.*
Enjoyed this article? You can also read and engage with it on Medium:
Read on Medium