Optimizers: A Deep Dive into Gradient Descent, Adam, and Beyond
Optimizers are crucial in machine learning, helping models learn by adjusting the weights to minimize the loss function. Choosing the right optimizer can significantly impact your model’s speed and performance. This article explores some of the most common optimization algorithms, from basic Gradient Descent to advanced methods like Adam, including a discussion on smoothing techniques and the importance of learning rates.
1. Gradient Descent
Gradient Descent is the simplest and most widely used optimization algorithm. It minimizes the loss function by iteratively adjusting the model’s parameters in the direction of the steepest descent (negative gradient).

- Pros: Simple to implement and understand.
- Cons: Can be slow for large datasets and may converge to local minima rather than the global minimum. The learning rate η plays a crucial role in the convergence of Gradient Descent. A small learning rate might lead to slow convergence, while a large one can cause the algorithm to overshoot the minimum, leading to divergence. Choosing the right learning rate often requires experimentation and fine-tuning.
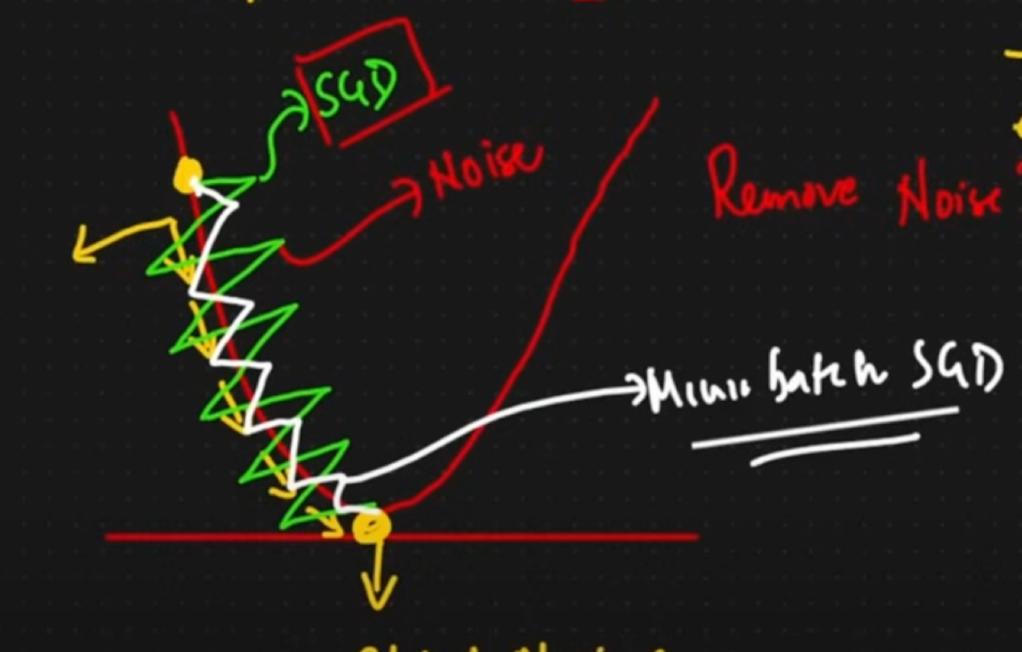
2. Stochastic Gradient Descent (SGD)
Stochastic Gradient Descent is a variation of Gradient Descent that updates the model parameters using a single data point (or a small batch) at each iteration rather than the entire dataset.
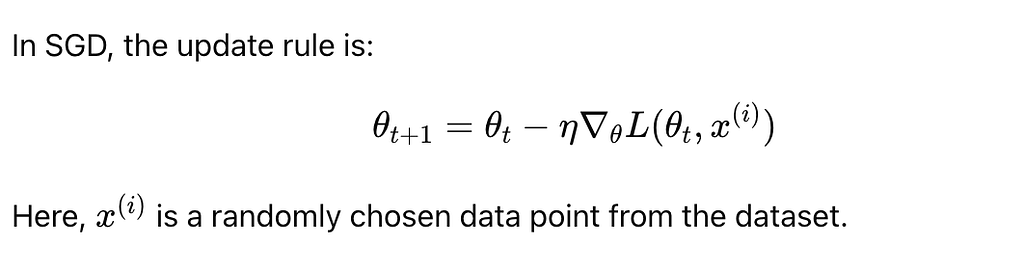
- Pros: Faster updates, especially for large datasets, and can escape local minima due to its stochastic nature.
- Cons: Noisy updates can lead to fluctuations in the loss function, making convergence harder. One way to mitigate the noise in SGD is by using a smoothing technique such as averaging the parameters over time. This can help stabilize the updates and improve the convergence behavior.
3. Mini-Batch Stochastic Gradient Descent
Mini-Batch SGD is a middle ground between batch Gradient Descent and Stochastic Gradient Descent. It updates the model parameters based on a small subset (mini-batch) of the dataset at each iteration.

- Pros: Reduces the noise of SGD while still providing faster convergence than batch Gradient Descent.
- Cons: Requires tuning of the mini-batch size and can be computationally expensive for large mini-batches. In Mini-Batch SGD, smoothing can be achieved by using techniques like exponential moving averages, where the parameter updates are averaged over time to reduce variance and stabilize convergence.
4. Stochastic Gradient Descent with Momentum
SGD with Momentum is an extension of SGD that helps accelerate convergence, especially in regions with small gradients. It does so by adding a momentum term that accumulates the past gradients’ direction.

- Pros: Faster convergence and can help escape local minima.
- Cons: Requires careful tuning of the momentum factor γ\gammaγ. In SGD with Momentum, the learning rate η\etaη and the momentum factor γ\gammaγ must be carefully chosen. A high momentum can help speed up convergence but may cause oscillations if combined with a large learning rate.
5. Adagrad
Adagrad (Adaptive Gradient Algorithm) adapts the learning rate for each parameter based on the magnitude of past gradients. This makes it particularly effective for sparse data and problems where the importance of features changes over time.

- Pros: Adaptive learning rate and works well with sparse data.
- Cons: The learning rate can become too small over time, leading to slow convergence Adagrad implicitly smooths the learning rate by adjusting it according to the sum of past gradients. However, this can cause the learning rate to decay too quickly, which is why variants like RMSprop are used to counteract this effect.
6. RMSprop
RMSprop (Root Mean Square Propagation) is a modification of Adagrad that introduces a moving average of squared gradients, helping to prevent the learning rate from decaying too quickly.

- Pros: Prevents the learning rate from decaying too quickly, leading to faster convergence.
- Cons: Requires careful tuning of the hyperparameters γ and η. RMSprop smooths the learning rate by averaging squared gradients over time. This helps stabilize the learning process, making RMSprop a popular choice for training deep networks.
7. Adam
Adam (Adaptive Moment Estimation) combines the benefits of RMSprop and SGD with Momentum. It maintains two moving averages, one for the first moment (mean) and one for the second moment (uncentered variance) of the gradients.

- Pros: Combines the benefits of momentum and adaptive learning rates, making it highly effective for many problems.
- Cons: Can sometimes be less effective in certain scenarios, and the choice of hyperparameters can be tricky. Adam automatically adjusts the learning rate based on the moments of the gradients. This makes it less sensitive to the initial learning rate, though fine-tuning is still essential for optimal performance.

*This post originally appeared on my Medium
.*
Enjoyed this article? You can also read and engage with it on Medium:
Read on Medium