From Pretraining to Policy Optimization: How LLMs Learn to Align with Us

The development of Large Language Models (LLMs) like GPT-4, Claude, and Gemini involves a multi-stage process. At a high level, this includes pretraining, post-training, and more advanced optimization methods like PPO, DPO, and GRPO. In this article, we’ll walk through each phase in detail — based on raw training insights and real-world methods used in industry.
Pretraining: Building the Foundation
Pretraining is the initial phase of training an LLM. At this stage, the model is exposed to a massive corpus of text to learn the general structure of language — syntax, semantics, and patterns — without being tuned for any specific task.
Goal*: Equip the model with a broad understanding of language, enabling it to learn linguistic structures and semantic relationships from vast amounts of data.*The model performs next-token prediction: given a sequence of text, it learns to predict what comes next.It learns to represent meaning, relationships, reasoning patterns, and factual information.However, it has no inherent task-specific skills — that’s where post-training comes in.
Post-Training: Specialization and Alignment

Once pretraining is complete, post-training refines the model, adapting it to specific tasks and aligning it with human intent. This step makes the model more useful and responsive to real-world applications.
*Post-training is where the model is specialized — often through supervised fine-tuning and reinforcement learning from human feedback (RLHF).*In recent years, post-training techniques have evolved significantly. While SFT and RLHF were once the dominant methods, new approaches like Direct Preference Optimization (DPO) and Generalized Policy Regularized Optimization (GRPO) are challenging the status quo.
Let’s break them all down.
Supervised Fine-Tuning (SFT)
SFT involves training a pretrained model on a smaller, labeled dataset, where both inputs and desired outputs are explicitly provided. This allows the model to adapt to a specific domain or task — e.g., summarizing legal documents, generating code, or answering customer support queries.
While SFT also uses next-token prediction, it differs from pretraining by using labeled data.### Why It Matters:
It allows task-specific adaptationIt introduces human-curated examples to guide the model It customizes the model’s behavior for high-stakes or specialized domains.
Still, SFT is limited in how far it can align behavior — especially when human preferences are complex or subtle. That’s why we need reinforcement learning.
Reinforcement Learning (RL) in LLMs

Reinforcement learning is a type of machine learning where an agent (policy) learns to make decisions by interacting with an environment, receiving rewards for good actions and penalties for bad ones.
Unlike supervised learning (where ground truth is known), RL focuses on exploration — trying actions, receiving feedback, and improving over time.
Core Concepts:
- Policy: The decision rule (often a neural network)
- State: A representation of the environment
- Reward: Feedback signal for success or failure
- Trajectory: A sequence of states and actions
- Discount Factor (γ): Determines how much the agent values future rewards.
- γ = 0 → focus only on immediate rewards
- γ = 1 → treat future and current rewards equally LLMs trained with RL optimize long-term quality of responses, rather than just copying outputs.
️ PPO — Proximal Policy Optimization
PPO is the most widely-used RL algorithm in language model post-training. It was used in OpenAI’s ChatGPT and many similar systems.
How PPO Works (RLHF Pipeline):
- Step 1: Collect Human Demonstration Data A dataset of ideal responses is created via human labelers.
- Step 2: Train a Reward Model Pairs of model responses are ranked by preference to train a model that scores them.
- Step 3: Optimize the LLM Using PPO The model is fine-tuned to maximize the reward score using Proximal Policy Optimization.
Advantages:
- Balances learning and stability
- Keeps updates within a “safe” range using clipping
- Helps avoid catastrophic forgetting or drifting too far from the base model
🪄 DPO — Direct Preference Optimization
Direct Preference Optimization (DPO) is a newer, simplified approach that skips the reward model.
Instead of modeling reward, DPO directly optimizes the policy to prefer outputs humans favor — using a contrastive loss between “preferred” and “rejected” responses.### Why It’s a Game-Changer:
- No reward model required
- Trains directly from human comparison data
- Easier and cheaper to implement DPO learns:
*If response A is better than B, increase the probability of A and decrease that of B.*It’s an elegant, efficient alternative to PPO that has shown comparable or better performance in several tasks.
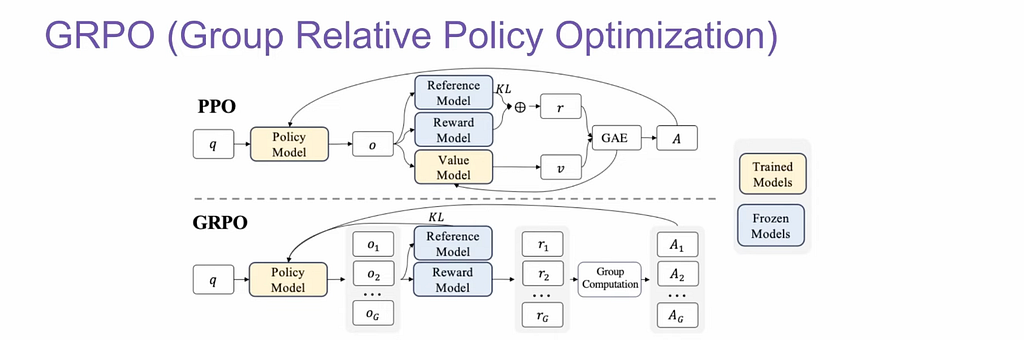
🧠 GRPO — Generalized Policy Regularized Optimization
GRPO generalizes DPO. It can handle a wider range of human feedback, including ranked lists, continuous scores, or soft preferences. It introduces regularization to prevent model collapse and encourages a balance between optimization and model retention.
Benefits of GRPO:
- Can simulate DPO, PPO, or new methods
- Works with noisy or soft feedback
- More flexible and robust than single-purpose techniques Though still experimental, GRPO represents a next-gen alignment method for building safe, steerable LLMs.
Challenging Old Assumptions
Until recently, it was believed that human-labeled data was necessary to teach structured reasoning and task-following behavior.
But new work, such as DeepSeek R1, challenges this belief — showing that emergent behavior and reading ability can arise even without traditional RLHF, via innovations in model scaling, architecture, or pretraining techniques.
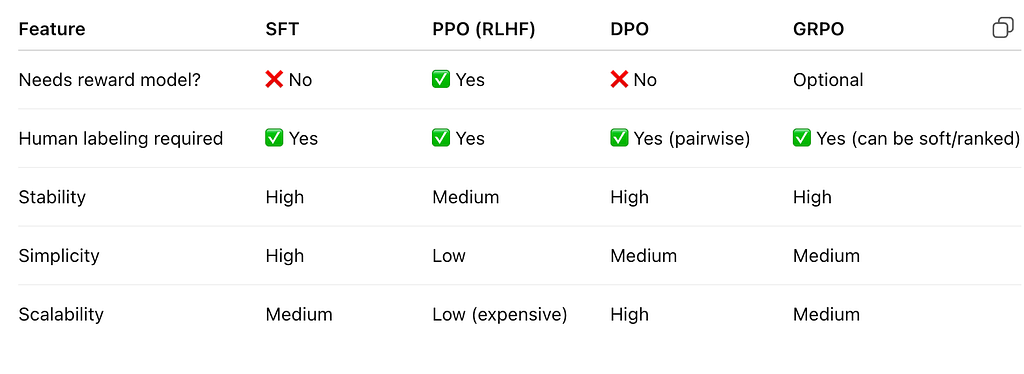
Training a powerful and aligned LLM requires multiple phases:
- Pretraining: General linguistic and world knowledge
- SFT: Task specialization with labeled data
- RLHF/PPO: Preference alignment through reward optimization
- DPO/GRPO: Efficient, scalable alternatives that directly optimize human-aligned behavior As the field evolves, the goal remains the same: to build models that are not only smart, but also safe, helpful, and aligned with human values.
*This post originally appeared on my Medium
.*
Enjoyed this article? You can also read and engage with it on Medium:
Read on Medium